SEO算法:深度解读搜索引擎倒排索引算法原理及工作机制

今天顺时运营团队给大家分享一下有关搜索引擎倒排索引算法的一些事情,为什么要讲倒排索引呢?因为当用户搜索一个词的时候,返回的搜索结果页面就是经过倒排索引和一系列算法过滤后的结果排序,大家做SEO苦苦追求的不就是关键词排名的高低吗?
说的通俗一点,其实搜索引擎的索引就好比是我们平时看书时的目录,为了让大家更快找到自己所需要的内容。比如像导航网站其实就是互联网上小型索引的索引结构案例,上面会有一些具体的分类比如新闻、电影、小说、图片等等分类板块,方便用户可以快速的找到自己所需要的内容。
索引也是搜索引擎中最为核心的技术之一,因为在大量的网页中,怎样才能更快、更精准的找到用户查询这个词的搜索意图。因为基本上所有搜索引擎的目标都是为了给用户提供:更全、更快、更准的搜索结果,这也是搜索引擎所存在的价值。
那么第一点就是通过蜘蛛爬取页面实现,而更快就要通过“索引技术”实现,倒排索引则是这其中的一环,其中又包括链接分析等等。
下面顺时运营团队来带着大家深度的解读一下到底什么是搜索引擎倒排索引?倒排索引算法的工作原理和机制又是什么?

一、倒排索引简介
倒排索引(英文:Inverted Index),是一种索引方法,常被用于全文检索系统中的一种单词文档映射结构。
现代搜索引擎绝大多数的索引都是基于倒排索引来进行构建的,这源于在实际应用当中,用户在使用搜索引擎查找信息时往往只输入信息中的某个属性关键字,如一些用户不记得歌名,会输入歌词来查找歌名;输入某个节目内容片段来查找该节目等等。
面对海量的信息数据,为满足用户需求,顺应信息时代快速获取信息的趋势,聪明的开发者们在进行搜索引擎开发时对这些信息数据进行逆向运算,研发了“关键词——文档”形式的一种映射结构,实现了通过物品属性信息对物品进行映射时,可以帮助用户快速定位到目标信息,从而极大降低了信息获取难度。
倒排索引又叫反向索引,它是一种逆向思维运算,是现代信息检索领域里面最有效的一种索引结构。
二、倒排索引概述
在关系数据库系统里,索引是检索数据最有效率的方式,但对于搜索引擎,它并不能满足其特殊要求:
1、海量数据:搜索引擎面对的是海量数据,像Google、百度这样大型的商业搜索引擎索引都是亿级甚至百亿级的网页数量,面对如此海量数据 ,使得数据库系统很难有效的管理。
2、数据操作简单:搜索引擎使用的数据操作简单,一般而言 ,只需要增、 删、 改、 查几个功能,而且数据都有特定的格式,可以针对这些应用设计出简单高效的应用程序。
而一般的数据库系统则支持大而全的功能,同时损失了速度和空间。
最后 搜索引擎面临大量的用户检索需求 ,这要求搜索引擎在检索程序的设计上要分秒必争,尽可能的将大运算量的工作在索引建立时完成,使检索运算尽量的少。一般的数据库系统很难承受如此大量的用户请求 ,而且在检索响应时间和检索并发度上都不及我们专门设计的索引系统。
三、举例说明
为了更好的理解,这里针对以下专业术语名词进行简单解释。
文档:我们是以网页的形式看到互联网页面的,而网页中包含很多的东西,比如:TXT、EXCEL、PDF等等很多各式各样的文件都被成为文档。
文档集合:由很多的文档组成一个集合,称为文档集合。
文档编号:互联网上每一个文档都有各自且独一无二的编号。
单词编号:每个单词都有各自的唯一编号,用编号来代表这个单词或、短语者句子。
倒排索引:是在搜索引起的索引库中,以单词对应网页的一种存储的形式,可以根据单词快速的获取相关的文档。
其实倒排索引非常的简单,下面顺时运营团队就结合一些特征案例来渐渐深入的分析这个算法,大家先了解一些基本的思路即可。
大家先看下下面这张图:

上图是每个文档编号对应的不同文档,如编号“1”对应“小明吃早饭”,编号“2”对应“小明早上吃了什么”,以此类推。
另外由于中文和英文的文化属性不相同,中文的汉字之间没有明显像英文单词那样的分隔符,索引首先对中文要进行一下分词(下面举例中暂时不去掉停止词),这样就把一句话变成了一个个的词组。
如下图所示:
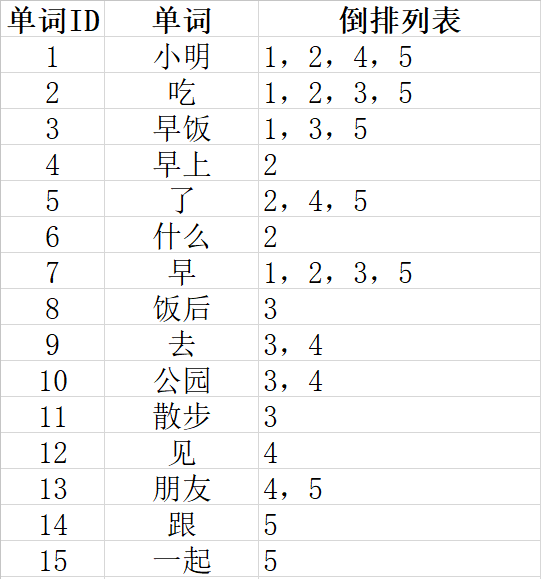
上图单词的ID记录了每个单词的编号,第二列是编号所对应的单词,第三列是哪几个文档中包含了这个单词。
比如单词“小明”,其其单词编号为“1”,倒排列表“1,2,4,5”,表示这几个文档集合中都包含了这个单词。实际上搜索引擎更为复杂,不仅仅记录了单词的文档编号,还记录了单词的频率(TF,什么意思呢?很多seo从业者都在说关键词的密度,
市面上计算页面中关键词密度的计算公式有三个:
公式一: 关键词次数/页面总字数 x 100% 公式二: 关键词次数/页面总字数/关键词字数 x 100% 公式三: 关键词次数/页面分词数量 x 100%
先不讨论哪个公式的计算方式更加精准,我们发现公式中都出现了关键词的次数,那这个TF就是该单词在页面中出现的次数)。
这个TF在搜索引擎计算搜索结果排序时,分析查询词和文档库中哪个文档更为相关的一个参考因素。

上图是比较复杂的,我们来看看文档频率为多个文档包含这个单词,如:“小明”在“4个文档”中出现了。“吃”在“4个文档”中出现了,后面的以此类推。倒排列表小明 (1;1<1>),1为文档1,中间的1为这个词在这个文档中出现的频率,<1>是这个词在文档中出现的位置1,即在文档中第一个词。
搜索引擎可以说是这个世界上最复杂的程序之一了,且各家搜索引擎公司公开的算法都有很多,有兴趣的同学们可以网上查查这些搜索引擎公司所申请专利的一个文档,文档中有各种专利技术,会涉及到高等数学等等知识,如果你能坚持的去看并且结合实践的话,那么你以后再操作网站SEO的时候思路就会很清晰了。
总结
经过以上的举例说明,相信大家都能够很好的理解搜索引擎倒排索引算法的原理和过程了。更多的了解搜索引擎的排序算法机制可以更好的帮助我们做好网站的SEO排名,当然,也不需要我们做到像专业的算法工程师那样的水平,即便只是知道其工作原理对我们来说也是有很大的好处的。
好了,本次有关倒排索引算法的内容就讲到这里吧!更多有关搜索引擎排序算法的知识和SEO技术教程顺时运营团队会持续分享,欢迎大家持续关注学习!
本文由顺时运营团队根据行业工作经验及互联网相关知识内容整理后发布,旨在传播分享有价值的内容,内容如有错误或侵犯了您的权益,请提供相关材料联系本站核实修改或删除处理。
本文链接:http://yunying.shunshi.vip/article/15.html


最新文章
-

网站收录之后没有排名怎么办?详细原因分析!
2023-05-10 -
网站不被搜索引擎收录怎么办?教你如何提高网站收录率!
2023-05-10 -

网站安全防护指南:如何判断网站被黑?被黑后如何处理?
2022-08-10 -

网站被非法渗透发布大量敏感信息导致降权,如何恢复?
2022-08-10 -

网站被黑了怎么办?(网站安全加固技巧)
2022-08-10 -

三种方法教你网站如何禁止国外IP访问(亲测有效)
2022-08-01 -

2022年的百度搜索,还能放心使用吗?
2022-05-14 -

Dynadot4 LLC是哪家域名注册商?(Dynadot域名注册商介绍)
2022-05-14
热门文章
-
网站收录之后没有排名怎么办?详细原因分析!
2023-05-10 -
网站不被搜索引擎收录怎么办?教你如何提高网站收录率!
2023-05-10
有话要说...